seata分布式事务(二)
之前记录了seata的安装,这次记录一下seata中AT和XA的实现原理,这两种模式都是基于两阶段提交协议,只记录这两种类型是目前我使用到了这两种类型所以记录一下他们的原理。
了解这两个设计模式之前需要先了解seata中的领域模型,以及领域模型中各个角色的功能和作用:
事务管理者(TM):这个角色用于管理全局的事务,他会接收每一个分支事务的反馈并做出判断,之后再通知其他的分支事务是提交还是回滚。例如:分支事务A、B和C是一个全局事务,A和B两个分支执行成功了并且反馈了提交的请求,但是分支事务C事务提交失败反馈回滚请求,那么TM就会通知分支事务A和B进行事务回滚。
资源管理者(RM):官方解释是Seata 中用于管理资源的实体,一般情况下等同于微服务中的提供方(provider),管理其所在服务中的资源,如数据库资源等。我个人理解为是一条数据库连接,用来执行分支事务的提交或则回滚功能。
事务协调者(TC):如果是TM(事务管理者)用来管理全局事务,那么TC就用来管理分支事务,它操作着RM(资源管理者)进行本地事务的提交或则回滚,并将RM的执行结果反馈给TM(事务管理者)。
AT模式:他是seata独有的模式,他的进行分布式事务的原理如下:
1.记录SQL的信息,包括但不限于操作类型(update、insert和delete)、表名、条件名和条件值。
2.根据这个条件生成一个查询语句并生成一个前镜像,比如:业务语句为update set 字段1 = xxx1 from 表名 where 字段1 = xxx2;那么就会根据这个语句生成一条查询语句 select 字段1,字段2,字段3, ...... from 表名 where 字段1 = xxx1,并为记录这个sql语句的结果。
3.执行业务语句,并且为执行后的结果也生成一个查询语句,这次的查询条件是这条语句中的主键,比如:select 字段1,字段2,字段3, ...... from 表名 where id = xxx
4.将前后两个镜像的合并在一起组成一条回滚日志,并将这条回滚日志插入UNDO_LOG(这个表可以看上一章有详细的字段)表中,官方文档中的模拟数据如下:
{
"branchId": 641789253,
"undoItems": [{
"afterImage": {
"rows": [{
"fields": [{
"name": "id",
"type": 4,
"value": 1
}, {
"name": "name",
"type": 12,
"value": "GTS"
}, {
"name": "since",
"type": 12,
"value": "2014"
}]
}],
"tableName": "product"
},
"beforeImage": {
"rows": [{
"fields": [{
"name": "id",
"type": 4,
"value": 1
}, {
"name": "name",
"type": 12,
"value": "TXC"
}, {
"name": "since",
"type": 12,
"value": "2014"
}]
}],
"tableName": "product"
},
"sqlType": "UPDATE"
}],
"xid": "xid:xxx"
} 通过这个数据可以很直观的看到,他记录了业务语句执行前后的变化、业务语句的类型、业务语句和所操作的类型还有xid(全局事务id)和branchId(分支事务id,这个分支事务也就是本地事务的id,因为分布式事务肯定是多个的所以要把他们所有的分支事务id都要记录下来),后续如果除了问题就可以通过这个回滚日志记录的信息进行事务的回滚。
5.TM等待所有的事务反馈并作出相应的操作,每个TC通过RM去执行本地事务,然后记录结果如果全部通过了那么TM就会发送一条异步消息,去执行一个删除UNDO_LOG回滚日志的操作,反之如果有分支事务失败的话,那么就回通知其他分支事务回滚。
6.如果是要回滚的话,TC接到TM的指令后又会开启一个本地事务,然后通过xid和branchId找到UNDO_LOG表中相应的数据然后进行数据校验,如果UNDO_LOG表中记录的数据和现在的数据不同(也就是产生了脏数据)说明这条数据被除了当前的全局事务以外的事务进行了修改,那么这个时候就要根据用户设置的策略来进行修改,比如如果不一致放弃回滚或者直接覆盖脏数据等。反之没有产生脏数据的话就会使用回滚日志里记录的信息进行数据的还原。
AT的隔离级别:
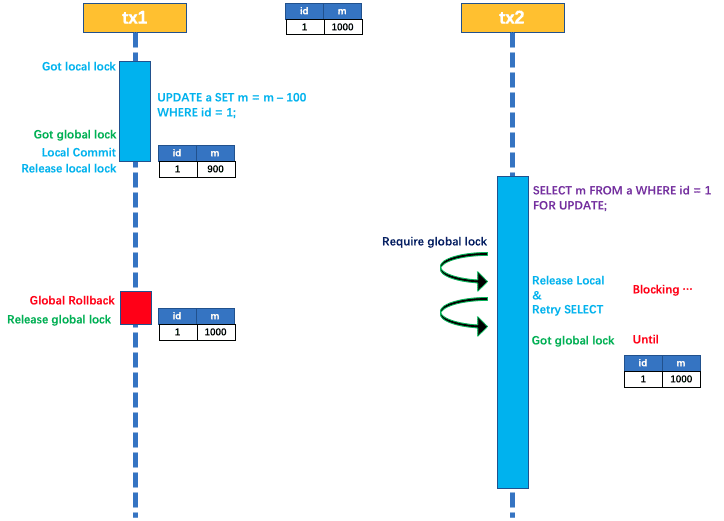
写隔离:每个全局事务都要拿到全局锁和本地所锁,在一个事务没有释放出本地锁和全局锁的时候另一个事务也是无法拿到锁从而对数据进行修改的,这样就能保证不会出现脏数据的情况,当前事务(这里称呼他为事务A)提交完毕之后就会释放本地锁(全局锁不会释放),这是其他事务(这里称呼他为事务B)就可以拿到本地锁,如果这是时候事务A要进行回滚就需要重新获取本地锁,这时本地锁是被事务B占有的就会形成死锁。所以seata设置了超时机制来避免这种死锁的发生,事务B在一定时间内拿不到全局锁就会放弃获取全局锁并释放本地锁,这时候事务A就可以重新获取本地锁进行回滚,具体流程图如下(此图来着seata官方文档):
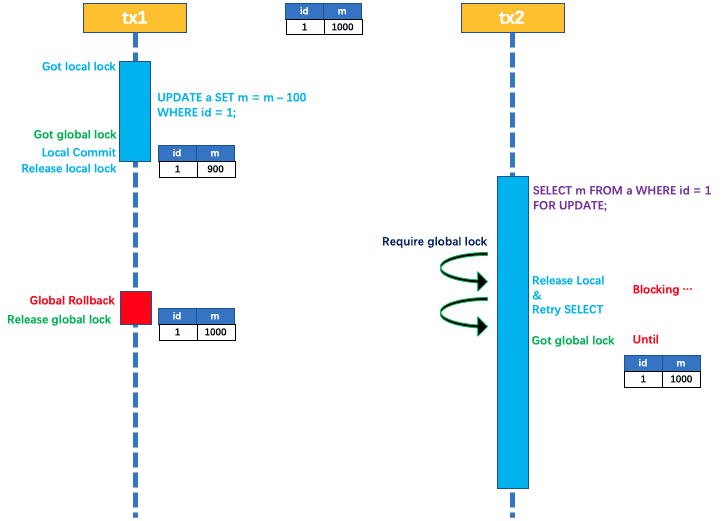
读隔离官方介绍:在数据库本地事务隔离级别 读已提交(Read Committed) 或以上的基础上,Seata(AT 模式)的默认全局隔离级别是 读未提交(Read Uncommitted)。这种情况,就是说明使用AT模式时会出现脏读的情况,如果要保证数据强一致性(读已提交)官方给的解决方案是通过 SELECT FOR UPDATE 语句的代理,他也是通过拿到全局锁保证数据的一致性,如果拿到全局锁说明数据是已经提交过的正常数据,具体流程图如下(此图来着seata官方文档):
XA模式:其实XA模式和AT模式差不多,他们的区别在于AT在TC分支事务操作完毕后就会直接把操作结果反馈给TM,而XA模式则是等待所有TC完成操作后才会统一提交所有分支事务的操作结果。就比如有3个事务分别是:事务A、事务B和事务C,在AT模式下事务A先操作成功随之事务B操作失败那么就不会等待事务C的反馈,TM就会直接进行全局事务回滚。而XA模式下则需要等事务A、事务B和事务C都完成了之后才会统一反馈给TM进行全局事务的操作。这也导致了XA模式下的效率不如AT模式,但是这种统一提交的方式也恰好解决了AT会发生脏读的问题,在这个全局事务没有提交之前其他事务无法获取到本地锁和全局锁那么就不会有读取到脏数据的情况。
总结:如果要求数据一致性高,那么可以选择牺牲一部分性能使用XA模式,反之如果对数据一致性需求没有那么高的并且允许读取脏数据的情况下,可以使用性能高一些的AT模式。
- 本文标签: 综合
- 本文链接: https://ssadan-blog.cn/article/18
- 版权声明: 本文由sadan原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权